In this post I am going to go through my implementation of different search algorithms for path finding based on Grid map. First, I will start with the global search algorithms such as breadth first and depth first. Then I will present the A* algorithms and how we can optimize the code. As usual I am going to use C++ to do the programming.
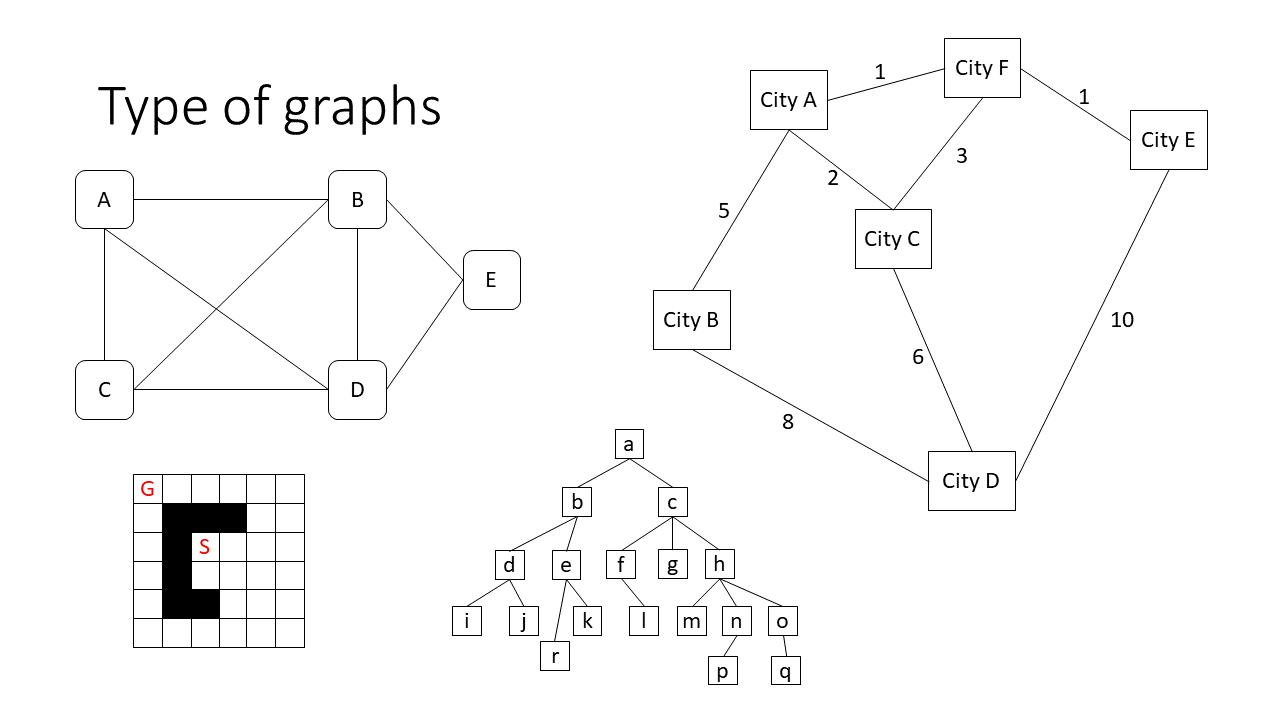
There are different type of graphs which shown in the image below.
In this project I define the map as a 2D vector std::vector
class Node {
public:
int x, y;
State state;
bool visited;
int parent_x;
int parent_y;
int G;
int H;
int cost;
Node(int _x, int _y, State _state, int px, int py, int g =0, int h =0) {
x = _x;
y = _y;
state = _state;
parent_x = px;
parent_y = py;
visited = false;
G = g;
H = h;
if (state == State::kObstecal)
{
cost = 255;
}
else
{
cost = 0;
}
}
};So, let’s start talking about the search algorithms. The search algorithms is used to solve the problem of problem to find the shortest path between two point. There are two type of search algorithms which is uniformed search and guided algorithm.
Uniformed search algorithm has no other information despite the start position and the goal position, where it searches all adjacent node until it finds the goal. There are two approaches we will present in this work which is the breadth-first search and depth-first algorithms.
Breadth-first search
The figure below explains how breadth-first search work by explore all the adjacent node before it moves to the child of the node.

Every time the algorithm opens new Node it checks if the goal has been reaching or not, the continue exploring the remaining. The figure below shows the algorithms steps.

And the code is shown below, where is it take three input and return string. The input is a 2D grid, start position and the goal position. I used queue to store the open node. The reason to use queue is that this data structure allowed for the first in last out FILO, which save the time in organize the data.
string BreadthFirst(vector < vector<Node>>& grid, int start[2], int goal[2]) {
// step 1: initialize nodeList and add the start node to the list
queue <Node> openList;
int x = start[0];
int y = start[1];
AddToOpenList(x, y, 0, 0, grid, openList);
// step 3: check if the list is empty
while (!openList.empty())
{
// step 5: dequeue node as currentnode and remove it from the list
Node currentNode = openList.front();
// remove the first element
openList.pop();
x = currentNode.x;
y = currentNode.y;
//cout << x << "," << y << "\n";
grid[x][y].visited = true;
grid[x][y].state = State::kVisited;
// step 6: check if the current node is the goal
if (x == goal[0] && y == goal[1])
{
RetracePath(start, goal, grid);
grid[start[0]][start[1]].state = State::kStart;
grid[goal[0]][goal[1]].state = State::kFinish;
return "Path found";
break;
}
// step 7: get the neighbors of the current node
ExpandNeighbor(currentNode, openList, grid);
}
return "No path Found";
}I wrote a functions to expand the neighbor of the current node where it check the four direction of the node which top, right, bottom and left. Note that this function made as a template so I can change the openList vector.
// this function used to expand the neightbor of the cuurent Node
template<class listTT>
void ExpandNeighbor(Node currentNode, listTT& openList, vector<vector<Node>>& grid) {
int x = currentNode.x;
int y = currentNode.y;
for (auto neighbor : delta)
{
int x2 = x + neighbor[0];
int y2 = y + neighbor[1];
if (CheckValidCell(x2, y2, grid) == 1)
{
AddToOpenList(x2, y2, x, y, grid, openList);
grid[x2][y2].state = State::kVisited;
}
}
}CheckValidCell is another function used to test if the node is accessible.
bool CheckValidCell(int x, int y, std::vector<std::vector<Node>>& grid)
{
bool on_grid_x = (x >= 0 && x < grid.size());
bool on_grid_y = (y >= 0 && y < grid[0].size());
if (on_grid_x && on_grid_y)
{
State nodeState = grid[x][y].state;
if (nodeState != State::kObstecal && grid[x][y].visited == false)
{
return grid[x][y].state == State::kEmpty;
}
}
return false;
}AddToOpenList is function designed to add the node into openList due to the complexity of node class.
template <class listT>
void AddToOpenList(int x, int y, int p_x, int p_y, vector<vector<Node>>& grid, listT& openList) {
Node currentNode{ x, y, State::kClose, p_x, p_y };
openList.push(currentNode);
grid[x][y].parent_x = p_x;
grid[x][y].parent_y = p_y;
grid[x][y].state = State::kClose;
} And finally, we have the function to trace the path from finish to start. Here we will see why we define the parent for each node. Every current node expands four new node where the current node will be the parent of these node.
vector<Node> RetracePath(int startNode[2], int goal[2], vector<vector<Node>>& grid)
{
vector<Node> path;
Node currentNode = grid[goal[0]][goal[1]];
int x = currentNode.x;
int y = currentNode.y;
while (x != startNode[0] || y != startNode[1])
{
path.push_back(currentNode);
grid[currentNode.x][currentNode.y].state = State::kPath;
currentNode = grid[currentNode.parent_x][currentNode.parent_y];
x = currentNode.x;
y = currentNode.y;
}
reverse(path.begin(), path.end());
cout << "Path length: " << path.size() << "\n";
return path;
}
The second uniformed search is the depth-first where it explores the depth of every node before it goes it its neighbor. The figure below shows the search of the depth first.
Depth-first search
The second uniformed search is the depth-first where it explores the depth of every node before it goes it its neighbor. The figure below shows the search of the depth first.

The figure below shows the steps of depth first algorithm which follow the same steps.

The below code shows the function of the depth first algorithms that has the same input of breadth-first and the same output. But these algorithms use stack to store the open list. The reason to use stack because stack worked based on the first in first out FIFO.
string DepthFirst(vector<vector<Node>>& grid, int start[2], int goal[2]) {
// step 1: initialize openList and add that start node
stack <Node> openList;
int x = start[0];
int y = start[1];
AddToOpenList(x, y, 0, 0, grid, openList);
// step 2: check iof open list is not empty
while (!openList.empty())
{
// step 3: get the currentNode from the stack
Node currentNode = openList.top();
openList.pop();
x = currentNode.x;
y = currentNode.y;
//cout << x << "," << y << "\n";
// step 4: mark the node as visited
grid[x][y].visited = true;
grid[x][y].state = State::kVisited;
// step 5: check if the node is the goal
if (x == goal[0] && y == goal[1])
{
RetracePath(start, goal, grid);
grid[start[0]][start[1]].state = State::kStart;
grid[goal[0]][goal[1]].state = State::kFinish;
return "[INFO] path was found...";
break;
}
// step 6: check the neighbor of the node
ExpandNeighbor(currentNode, openList, grid);
}
return " [INFO] No path was found...";
}The output is show below of both the breadth-first and the depth-first. As can be seen that the number of nodes explored is shown in purple and the bath is shown in green and the yellow is the wall.
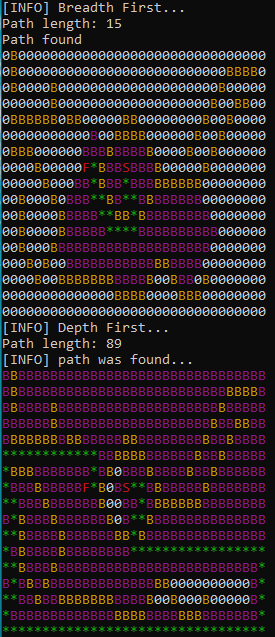
As can be seen in the output that the explore in both methods are different due to the nature of the explore way. Both algorithms able to reach the path but the final path length is different also the number of node explore differe.
A star Algorithm
Now we are going to use a heuristic function algorithm that use measure to chose the shortest path with minimum exploring nodes. What we mean by heuristic function is that the algorithm use information such as the moving cost, and the distance from the current node to the goal then decided on which node move. The same step node based on the cost function. In this work we used the smallerst to largest.
Revisiting the Node class there are two variable that we did not used in the uniformed search which is H and G. Where H represent the distance between the node and the gaol and we measure it using euclidean distance. And G is the move cost which is accomulated from the start node to the current node.
We update the expandNeighbors function by adding the measurment of heuristic and compute the cost movement.
/**
* Expand current nodes's neighbors and add them to the open list.
*/
void ExpandNeighbors(Node& currentNode,
std::priority_queue<Node, std::vector<Node>, CompareDis>& openList,
std::vector<std::vector<Node>>& grid, int goal[2])
{
// Get current node's data.
int x = currentNode.x;
int y = currentNode.y;
int g = currentNode.G;
// Loop through current node's potential neighbors.
for (auto neighnor : delta)
{
// Check that the potential neighbor's x2 and y2 values are on the grid and not closed.
int x2 = x + neighnor[0];
int y2 = y + neighnor[1];
// Increment g value, compute h value, and add neighbor to open list.
if (CheckValidCell(x2, y2, grid) == 1 && grid[x2][y2].visited == false)
{
int cost = grid[x2][y2].cost;
int g2 = g + 1;
int h2 = Heuristic(x2, y2, goal[0], goal[1], cost);
AddToOpen(x2, y2, g2, h2, x, y, openList, grid);
grid[x2][y2].visited = true;
}
}
}the heuristic function is shown below.
int Heuristic(int x1, int y1, int x2, int y2, int cost = 0)
{
return std::sqrt(std::pow(x2 - x1,2) + std::pow(y2 - y1,2));
}The search algorithm is show below.
We can check out the search algorithms function.
std::vector<Node> Search(std::vector<std::vector<Node>> &grid, int init[2], int goal[2]) {
std::priority_queue<Node, std::vector<Node>, CompareDis> openList;
std::vector<int> path;
int x = init[0];
int y = init[1];
int h = Heuristic(x, y, goal[0], goal[1]);
AddToOpen(x, y, 0, h, 0, 0, openList, grid);
int threshold = 0;
//while open vector is non empty {
while (!openList.empty()) {
//Get the x and y values from the current node,
auto currentNode = openList.top();
openList.pop();
x = currentNode.x;
y = currentNode.y;
grid[x][y].state = State::kVisited;
// Check if you've reached the goal. If so, return grid.
if (x == goal[0] && y == goal[1])
{
int _goal[2]{ x,y };
auto path = RetracePath(init, _goal, grid);
grid[init[0]][init[1]].state = State::kStart;
grid[goal[0]][goal[1]].state = State::kFinish;
std::cout << "Path found!\n";
// PrintPath(path);
return path;
}
// If we're not done, expand search to current node's neighbors.
ExpandNeighbors(currentNode, openList, grid, goal);
}
std::cout << " No path found!" << "\n";
return std::vector<Node>{};
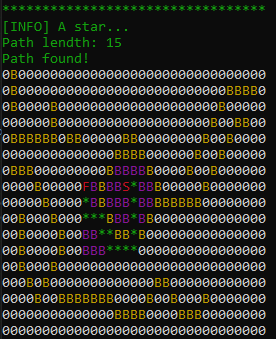
}The reseault is shown in the figure below. Where the the exoplored node is smaller and the path is the shortest compare to the other two algoritms.
Conclusion
As can be seen there are two type of search algorithms which uninformed search and informed search. In the uniformed search the expolation occur unguided which based on which node to explore first, while the informed search algorithm it used information and heuristic function.
Overall, the step of applying the algorithms is same but using different type of data structures simplified the implementation process.
you can get the full code here For the full code check this link Guthub_code